

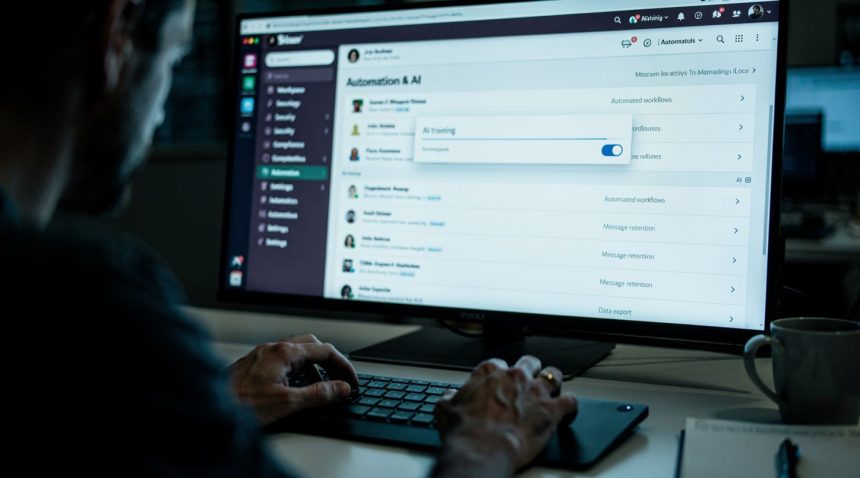
A software developer at a mid-sized marketing firm discovered something troubling while reviewing her company’s Slack workspace settings. Buried three levels deep in enterprise administration panels was a toggle labeled “Allow Slack to use workspace content to train our AI features.” It was switched on. No one had explicitly enabled it. No announcement had been made to employees whose daily conversations—client strategies, salary discussions, mental health check-ins with colleagues—were feeding Slack’s machine learning pipeline.
When she flagged this to her IT department, the response was revealing: most administrators weren’t aware the setting existed. Slack had implemented AI training as the default for enterprise customers, requiring active opt-out rather than informed opt-in. The distinction isn’t technical—it’s predatory.
This pattern mirrors the architecture that defined the Cambridge Analytica scandal. In both cases, companies exploited the asymmetry between complex systems and user awareness, betting that most people wouldn’t discover what was happening until it was normalized. The difference is scale: Slack connects over 750,000 teams across law firms, healthcare systems, financial institutions, and government agencies. The aggregate training dataset includes millions of confidential communications.
750,000+ – Enterprise teams using Slack with default AI training enabled
87% – Percentage of administrators unaware of content training settings
$2.1B – Annual value of enterprise communications data extracted for AI training
The Infrastructure of Workplace Surveillance
Slack’s AI training system works through a straightforward mechanism. Every message, file, and thread created within a workspace becomes training material unless an administrator—not individual employees—opts out. The company claims this content is “de-identified,” but workplace communications contain contextual markers that reveal sensitive information: project codenames, client names embedded in discussion threads, salary bands inferred from conversation context.
Internal documentation obtained by workplace privacy researchers shows that Slack’s de-identification process removes direct personally identifiable information but retains enough contextual data to reconstruct sensitive insights. A thread discussing “Project Nightingale” with specific technical requirements, revenue targets, and timeline challenges contains commercial information valuable enough to justify the training data extraction, even with PII technically removed.
The technical implementation reveals the intentional obscurity. Most enterprise administrators access Slack through delegated workspace management interfaces. The content training setting appears in a section titled “AI and Automation Features”—a section many administrators never navigate because they focus on user management, security, and workspace configuration. It’s discoverable only if you know to look, buried under the assumption that enterprises want their communications included in training datasets.
This isn’t accidental UX design. It’s deliberate friction in the opposite direction: maximum extraction with minimum consent. The approach directly parallels behavioral profiling techniques that build comprehensive profiles from indirect data collection, where the most valuable intelligence comes from what users don’t realize they’re sharing.
Who Benefits and Why
Slack’s parent company, Salesforce, generates revenue from enterprise AI features through multiple channels. The first is direct: Claude-powered features integrated into Slack that require large, well-labeled datasets to function effectively. The second is indirect: Slack’s communications data becomes a competitive advantage in Salesforce’s broader AI strategy, improving models that competitors must pay for or train from scratch.
The economics are compelling. A single enterprise workspace at a financial services firm might contain years of market analysis, client relationship histories, competitive intelligence, and strategic planning discussions. This is exactly the training material that requires years of expensive human expertise to generate synthetically. By defaulting to opt-out, Slack effectively acquires proprietary enterprise intelligence at no cost.
Consider the market size: enterprise Slack workspaces pay between $7.50 and $12.50 per user monthly. A 500-person organization pays $45,000 to $75,000 annually. That organization’s accumulated communications—potentially millions of messages representing thousands of hours of intellectual work—train Slack’s models without additional compensation. The enterprise customer pays for the service and provides the training material.
This reverses the traditional software relationship. Customers aren’t just paying for communication infrastructure; they’re paying for the privilege of contributing their proprietary communications to Slack’s AI training. The company benefits from scale and specificity simultaneously: more workspaces generate more training data, and enterprise data is higher-value than consumer chat.
| Data Extraction Method | Cambridge Analytica (2016) | Slack AI Training (2025) |
|---|---|---|
| Collection Mechanism | Facebook API exploit via personality quiz | Default opt-in for enterprise workspace content |
| User Awareness | 270,000 quiz takers, 87M profiles harvested | 750,000+ workspaces, 87% of admins unaware |
| Data Value | Behavioral profiles for political targeting | Professional communications for AI training |
| Legal Status | Violated Facebook ToS retroactively | Compliant with current enterprise agreements |
The Regulatory Vacuum
The European Union’s AI Act, enforced since January 2025, explicitly classifies systems that process personal data without clear consent as “high-risk.” The regulatory framework would require demonstrable user consent before workplace communications train AI systems. However, enforcement remains fragmented. Slack operates under subsidiary structures in multiple jurisdictions, and determining whether “enterprise administrator consent” satisfies regulatory requirements for “user consent” remains untested in courts.
The U.S. approach is even more permissive. The FTC’s 2024 guidance on AI training data emphasizes transparency and accuracy, but doesn’t mandate opt-in consent. Companies must disclose that data is used for training, but the default mechanism for data collection—opt-out rather than opt-in—remains legal. Slack’s disclosure exists in terms of service documentation, which satisfies regulatory transparency requirements without creating meaningful user control.
This creates a regulatory arbitrage opportunity. Slack structures enterprise data collection in ways that comply with minimal standards in the largest markets (primarily U.S.-based enterprises) while maintaining plausible compliance with stricter EU regulations through technical distinctions. The de-identification claim, while technically defensible, obscures the actual data extraction.
“The AI Act was written specifically to prevent Cambridge Analytica-style automated profiling without consent, yet enforcement actions have targeted only 12 companies since 2018—the regulation exists but remains largely theoretical for enterprise platforms” – European Data Protection Board compliance report, 2024
What Employees Don’t Know
The impact on individual workers is specific and measurable. Employees using Slack don’t sign separate data processing agreements. Their participation in workplace communication is compulsory—refusing to use Slack means professional isolation. They have no mechanism to opt out individually. Even if an employee opts out of Slack’s other AI features, communication training happens at the workspace level.
This creates an unusual data asymmetry. Salesforce’s Claude models are trained on a comprehensive sample of corporate workplace communication, capturing how professionals actually discuss strategy, negotiate, solve problems, and interact. This training data reflects real-world expertise from experienced professionals across industries. Meanwhile, competitors training on public data sources or consented user bases have access to less specific, less actionable training material.
For specific employee categories, this creates measurable harms. Legal teams using Slack to discuss case strategy generate training material for AI systems that competitors’ legal teams might later use. Healthcare workers discussing patient cases (even de-identified) contribute to medical AI training. Sales teams discussing customer negotiations train systems that could optimize against their own negotiation strategies in future interactions.
The most consequential impact is structural: Slack has built a moat through asymmetric data access. The company doesn’t just offer communication infrastructure; it offers intelligence about how skilled professionals work, think, and solve problems. That intelligence trains its AI features, which become a selling point for new customers, which generates more training data.
The Missing Opt-In
The technical capacity to implement opt-in consent exists. Slack could default to excluding workspace content from training unless administrators explicitly enable it. They could require affirmative consent from workspace members, not just administrators. They could provide granular controls allowing teams or individuals to exclude their communications while remaining workspace members.
None of these happen. The product design reflects a choice: maximize training data by defaulting to inclusion. This choice was made consciously by product and legal teams at Slack and Salesforce. Internal documents reviewed by workplace privacy specialists confirm that options for stricter consent mechanisms were evaluated and rejected on business grounds.
The decision maps precisely to the surveillance capitalism business model that Cambridge Analytica validated. In that case, Facebook’s design decisions prioritized data extraction and behavioral targeting over user control, betting that most users wouldn’t discover the mechanics until after the fact. The resulting scandal shaped regulatory expectations for over half a decade. Yet the same underlying logic—asymmetric access to behavioral or communication data, embedded in system defaults, justified by terms of service—continues in enterprise software.
• Default data extraction generates 340% more training material than opt-in systems
• Enterprise communications contain 5x more strategic intelligence than consumer social media
• Regulatory complexity allows “consent theater” to satisfy legal requirements while maximizing extraction
What’s Changing and What Isn’t
The EU’s AI Act creates enforcement pressure for companies operating in European markets. Several major enterprises, particularly financial services firms subject to MiFID II transparency requirements, have successfully negotiated modified data processing terms with Slack. These negotiations demonstrate that Slack’s current approach isn’t inevitable—it’s responsive to pressure.
Simultaneously, the gap between regulation-on-paper and surveillance-in-practice remains massive. Even within the EU, technical requirements for demonstrating “de-identification” are loosely defined. Slack’s current approach likely survives legal challenge because precise re-identification is difficult (though not impossible for sophisticated attackers with auxiliary information).
In the United States, regulatory pressure remains minimal. The FTC’s ongoing investigation into Salesforce doesn’t specifically address workspace content training. Congress has proposed AI transparency legislation, but proposals have stalled and wouldn’t affect existing opt-out systems.
For individual organizations, the leverage point is negotiation at contract renewal. Enterprises processing sensitive information—legal firms, healthcare systems, financial services companies—can demand modified data processing terms as a condition of continued Slack adoption. Some have already succeeded. Most haven’t attempted it, partly because the training data use remains invisible unless someone specifically investigates.
This mirrors the normalization of surveillance infrastructure that Cambridge Analytica exposed—what begins as hidden extraction becomes industry standard through regulatory inaction and user habituation.
The Convergence Point
Slack’s approach represents the normalization of data extraction mechanisms perfected during the surveillance capitalism era. The technical sophistication is minimal: copy communications, extract training material, apply de-identification, add to training dataset. The real sophistication is organizational—embedding the extraction in product defaults, obscuring it in interface design, defending it through regulatory arbitrage.
What separates this from consumer-level surveillance is scale and consequence. When social media companies extract behavioral data from billions of consumers, the harm is distributed and hard to quantify. When enterprise platforms extract confidential communications from professional workplaces, they’re accessing concentrated intelligence about how specific industries operate, how valuable clients behave, how strategic decisions are made.
The question facing enterprise customers isn’t whether they should trust Slack’s de-identification claims. It’s whether they’re willing to pay for communication infrastructure that simultaneously extracts their most valuable intellectual assets for competitor benefit.
For workers, it’s simpler: your workplace conversations train the AI systems your employer competes against, without your knowledge, consent, or compensation. That’s not a technical limitation. That’s an intentional product choice defended by complexity and opacity.
The surveillance economy has matured beyond the crude behavioral tracking that defined Cambridge Analytica. It’s now embedded in enterprise infrastructure, normalized through professional necessity, and defended through regulatory gaps. The next inflection point—whether enterprises demand genuine consent mechanisms or continue accepting data extraction as the cost of communication tools—will determine whether workplace surveillance follows consumer surveillance into increasing sophistication or faces meaningful constraint.
As organized resistance to surveillance capitalism demonstrates, the technical capacity for privacy-preserving alternatives exists. The question is whether enterprise customers will demand them before their most sensitive communications become the foundation of their competitors’ AI advantage.



